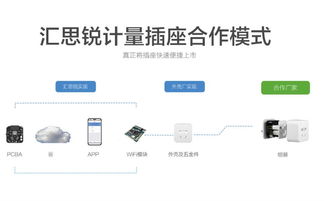
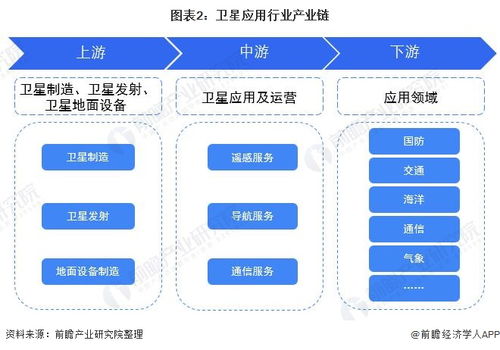
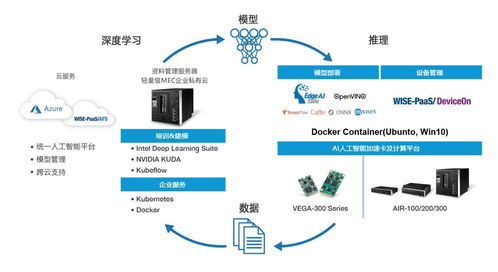
人工智能基礎軟件的開發是一個復雜且迭代的過程,它不僅依賴于先進的算法和模型,更離不開海量、高質量數據的支持。在利用大數據驅動人工智能(AI)系統構建時,開發者需在技術、倫理和工程實踐等多個維度保持高度警惕。以下是開發過程中必須注意的十二個關鍵點:
- 數據質量與預處理是基石:大數據并非“好數據”。原始數據往往包含噪聲、缺失值和不一致性。投入充足資源進行數據清洗、去重、歸一化和標注是確保模型性能的第一步。高質量的訓練數據直接決定了AI系統的上限。
- 明確問題定義與數據對齊:在收集數據之前,必須清晰定義AI系統要解決的具體業務問題。數據的特征、分布和規模應與問題場景緊密對齊,避免“用錘子找釘子”式的資源浪費。
- 重視數據多樣性與代表性:訓練數據應盡可能覆蓋真實世界的各種場景和邊緣案例,以減少模型偏見(Bias)并提高其泛化能力。例如,人臉識別系統的訓練數據需要涵蓋不同種族、年齡、光照條件和姿態。
- 保障數據安全與隱私合規:在數據采集、存儲、傳輸和處理的全生命周期中,必須嚴格遵守如GDPR、個人信息保護法等法律法規。采用數據脫敏、差分隱私、聯邦學習等技術,在利用數據價值的同時保護用戶隱私。
- 構建可擴展的數據管道:設計靈活、高效的數據流水線(Data Pipeline),能夠應對數據量的快速增長和來源的多樣化。這包括數據的實時/批量攝入、存儲、處理和服務化能力。
- 算法與模型的選擇與優化:根據問題性質和數據特點,選擇合適的機器學習或深度學習模型。避免盲目追求復雜模型,需在模型性能、推理速度、資源消耗和可解釋性之間取得平衡。持續進行超參數調優和模型壓縮。
- 實現高效的訓練與部署:利用分布式計算框架(如Spark、Ray)和專用硬件(如GPU/TPU)加速模型訓練。建立模型版本管理、持續集成/持續部署(CI/CD)流程,確保模型能夠平滑、可靠地部署到生產環境。
- 建立完善的監控與評估體系:模型上線并非終點。必須建立對模型性能、數據漂移(Data Drift)和概念漂移(Concept Drift)的持續監控機制。使用明確的評估指標(如準確率、召回率、F1分數、AUC等)并定期在獨立測試集上驗證。
- 確保系統的可解釋性與可追溯性:尤其是用于金融、醫療等高風險領域的AI系統,需要具備一定的可解釋性。記錄模型決策的關鍵數據依據和邏輯,以便在出現問題時進行追溯和審計,增強用戶信任。
- 關注倫理與偏見消除:主動檢測并努力消除數據及算法中可能存在的性別、種族、地域等偏見。建立倫理審查機制,確保AI系統的應用符合社會公序良俗,避免產生歧視性后果。
- 促進跨學科團隊協作:成功的AI項目需要數據科學家、算法工程師、軟件工程師、領域專家(如醫生、金融分析師)以及產品經理的緊密合作。確保業務需求與技術實現之間的有效溝通。
- 規劃長期維護與迭代路徑:人工智能系統需要持續的“喂養”和維護。規劃好模型的再訓練周期、新數據集成方案以及技術棧的升級路徑,以應對不斷變化的業務需求和外部環境。
人工智能基礎軟件的開發是一項系統工程,其成功不僅取決于技術的先進性,更依賴于對數據生命周期的精細管理、對工程最佳實踐的遵循以及對倫理風險的審慎考量。將這十二點融入開發流程,將為構建健壯、可靠且負責任的AI系統奠定堅實基礎。