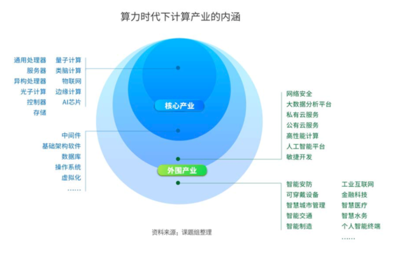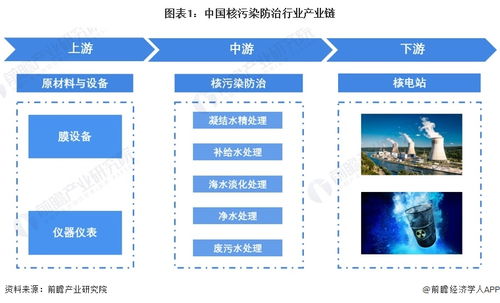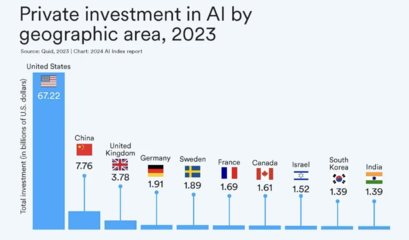
斯坦福大學發布的《2024年人工智能指數報告》為我們揭示了人工智能領域,特別是大模型及其基礎軟件開發的最新動態與深刻洞見。報告勾勒出AI技術浪潮的宏偉圖景,也指出了其發展道路上的關鍵機遇與艱巨挑戰。以下是基于報告解讀的十大核心前景與挑戰。
前景展望
- 性能持續突破,能力邊界拓寬:報告顯示,大模型在語言理解、代碼生成、多模態推理等任務上的性能持續快速提升,不斷突破以往的能力邊界,為更復雜、更通用的AI應用奠定了堅實基礎。
- 成本下降與效率提升:隨著算法優化、硬件進步(如專用AI芯片)和訓練方法的改進,大模型的訓練與推理成本呈現下降趨勢,能效比不斷提高,這有助于AI技術更廣泛地部署和應用。
- 開源生態日益繁榮:強大的開源模型(如Llama系列)和框架不斷涌現,降低了研究和應用門檻,促進了全球范圍內的創新協作,加速了AI技術的民主化進程。
- 垂直領域深度融合:大模型正與科學研究(如生物制藥、材料發現)、工程開發、內容創作等特定領域深度結合,催生專業化工具,提升各行業的生產力與創新能力。
- AI基礎軟件棧趨于成熟:從底層計算框架、編譯器、開發庫,到模型訓練、部署、監控工具鏈,一整套支撐大模型研發與應用的基礎軟件生態正在快速成形并趨于穩定和標準化。
主要挑戰
- 算力需求與能源消耗巨大:大模型的訓練和運行需要消耗海量算力和電力,報告警示其巨大的碳足跡和資源集中化可能帶來的環境與社會可持續性問題。
- 數據瓶頸與版權爭議:高質量訓練數據的獲取與清洗日益困難,數據枯竭風險初現。訓練數據涉及的版權、隱私問題引發廣泛的法律與倫理爭議。
- 可靠性與安全性隱患:大模型存在的“幻覺”(生成不準確信息)、偏見放大、對抗性攻擊脆弱性以及潛在濫用風險(如深度偽造、自動化惡意軟件生成)構成了嚴峻的安全挑戰。
- 評估標準與基準滯后:現有評估方法難以全面、可靠地衡量大模型在復雜、真實場景中的能力、安全性和對齊程度,亟需發展更科學的評估體系與基準。
- 人才短缺與技能鴻溝:頂尖AI研發人才,特別是精通大模型與基礎軟件開發的專家極度稀缺。社會整體面臨著適應AI時代所需的技能重塑與教育體系更新的巨大壓力。
****:斯坦福《2024年人工智能指數報告》清晰地表明,AI大模型及其基礎軟件開發正處于一個充滿活力與不確定性的關鍵十字路口。擁抱其帶來的 transformative 潛力,同時審慎、協同地應對其伴生的多重挑戰,需要產業界、學術界、政策制定者乃至全社會的共同努力。未來之路,既需技術創新勇往直前,也需治理框架與倫理思考同步護航。